
Problem statement
Data/messages are push to kafka topic from various services.
We need to centrally collect all messages from this topic to a given index in splunk.
Technology Used
Kafka, Kafka-Connect and Splunk Enterprise
Basic Requirement to complete this task
- We have running kafka cluster
- Splunk with administrative right
Like movie there are two side of this story
- Splunk Side Setup
2. Kafka Side Setup
Lets start with splunk side
Splunk Side Setup
a) We need to enable HTTP Event Collector
Settings → Data Input → HTTP Event Collector → Global settings

b) Create an Event Collector token
To use HEC, you must configure at least one token.
- Click Settings > Data > Data Input
- Click HTTP Event Collector -> New Token
- In the Name field, enter a name for the token.
- (Optional) In the Source name override field, enter a source name for events that this input generates.
- (Optional) In the Description field, enter a description for the input.
- (Optional) In the Output Group field, select an existing forwarder output group.
- Enable indexer acknowledgment for this token, click the Enable indexer acknowledgment checkbox.
- Click Next.
- (Optional) Confirm the source type and the index for HEC events.
- Click Review.
- Confirm that all settings for the endpoint are what you want.
- If all settings are what you want, click Submit. Otherwise, click < to make changes.
- (Optional) Copy the token value that Splunk Web displays and paste it into another document for reference later.

With this our first half is done. Intermission time have some snacks
Kafka Side Setup
a) kafka-connect-splunk jar
Download splunk-kafka-connect jar from https://github.com/splunk/kafka-connect-splunk/releases. For this walkthrough i am using splunk-kafka-connect-v2.0.2.jar
b) Connector configuration
- We need install splunk-kafka-connect-v2.0.2.jar across all Kafka Connect cluster nodes that will be running the Splunk connector.
- Kafka Connect has two modes of operation — Standalone mode and Distributed mode. We will be covering Distributed mode for the remainder of this walkthrough.
- open the connect-distributed.properties file that is availiable under conf folder.
Kafka ships with a few default properties files, however the Splunk Connector requires the below worker properties to function correctly. connect-distributed.properties can be modified or a new properties file can be created.# connect-distributed.properties
bootstrap.servers=<BOOTSTRAP_SERVERS> //KAFKA BROKERS
plugin.path=<PLUGIN_PATH> // this is path where kafka-connect jar is located i.e splunk-kafka-connect-v2.0.2.jar
c) Deploy Kafka Connect
Below command will deploy kafka-connect and should be done across all server of the kafka connect cluster.

With the Kafka Connect cluster up and running with the required settings in properties files,we can now manage our connectors and tasks via a REST interface. All REST calls only need to be completed against one host since the changes will propagate through the entire cluster.
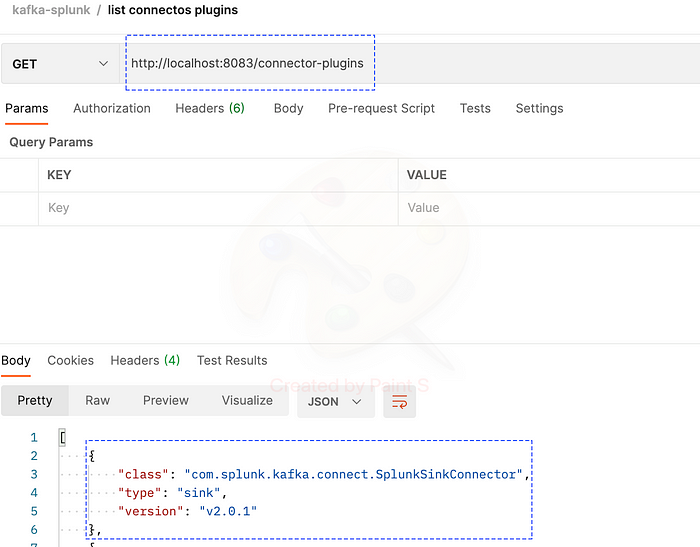
d) Verifying splunk connector installation
- curl http://<KAFKA_CONNECT_HOST>:8083/connector-plugins
The response should have an entry named :com.splunk.kafka.connect.SplunkSinkConnector
Full list of rest api to check status, and manage connectors and tasks:
# List active connectors
curl http://localhost:8083/connectors
# Get kafka-connect-splunk connector info
curl http://localhost:8083/connectors/kafka-connect-splunk
# Get kafka-connect-splunk connector config info
curl http://localhost:8083/connectors/kafka-connect-splunk/config
# Delete kafka-connect-splunk connector
curl http://localhost:8083/connectors/kafka-connect-splunk -X DELETE
# Get kafka-connect-splunk connector task info
curl http://localhost:8083/connectors/kafka-connect-splunk/taskse) Instantiate splunk connector
We can use rest api to instantiate splunk connector
curl --location --request POST 'http://<HOSTNAME>:8083/connectors' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "kafka-splunk-pipeline",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
"tasks.max": "1",
"splunk.indexes": "main",
"topics": "test",
"splunk.hec.uri": "http://santoshs-mbp:8088",
"splunk.hec.token": "1bdf9c2a-1cac-4e36-9f99-d4a713e64cb6",
"splunk.hec.ack.enabled": true,
"splunk.hec.ack.poll.interval": 20,
"splunk.hec.ack.poll.threads": 1,
"splunk.hec.event.timeout": 300,
"splunk.hec.raw": false,
"splunk.hec.track.data": true,
"splunk.hec.ssl.validate.certs": false,
}
}'So what do these configuration options mean? Here is a quick run through the configurations above. A detailed listing of all parameters that can be used to configure the Splunk Connect for Kafka can be found here.
- name: Connector name. A consumer group with this name will be created with tasks to be distributed evenly across the connector cluster nodes.
- connector.class: The Java class used to perform connector jobs. Keep the default unless you modify the connector.
- tasks.max: The number of tasks generated to handle data collection jobs in parallel. The tasks will be spread evenly across all Splunk Kafka Connector nodes
- topics: Comma separated list of Kafka topics for Splunk to consume
- splunk.hec.uri: Splunk HEC URIs. Either a comma separated list of the FQDNs or IPs of all Splunk indexers, or a load balancer. If using the former, the connector will load balance to indexers using round robin.
If your locall installed splunk then it is http://hostname:8088 - splunk.hec.token: Splunk HTTP Event Collector token (we have generated this while doing splunk side setup
- splunk.hec.ack.enabled: Valid settings are true or false. When set to true the Splunk Kafka Connector will poll event ACKs for POST events before check-pointing the Kafka offsets. This is used to prevent data loss, as this setting implements guaranteed delivery
- splunk.hec.raw: Set to true in order for Splunk software to ingest data using the the /raw HEC endpoint. false will use the /event endpoint
- splunk.hec.json.event.enrichment: Only applicable to /event HEC endpoint. This setting is used to enrich raw data with extra metadata fields. It contains a comma separated list of key value pairs. The configured enrichment metadata will be indexed along with raw event data by Splunk software. Note: Data enrichment for /event HEC endpoint is only available in Splunk Enterprise 6.5 and above
- splunk.hec.track.data: Valid settings are true or false. When set to true, data loss and data injection latency metadata will be indexed along with raw data.
We can verify installation of splunk-connector with below curl
curl — location — request GET ‘http://localhost:8083/connectors'
response for this should be connector name i.e “kafka-splunk-pipeline”
With this we have done all necessary things for kafka-splunk integration to work. Now post few messages on kafka topic and you can see them in Splunk










